How does OLS estimate regression coefficients? Shiny app
True model vs estimates
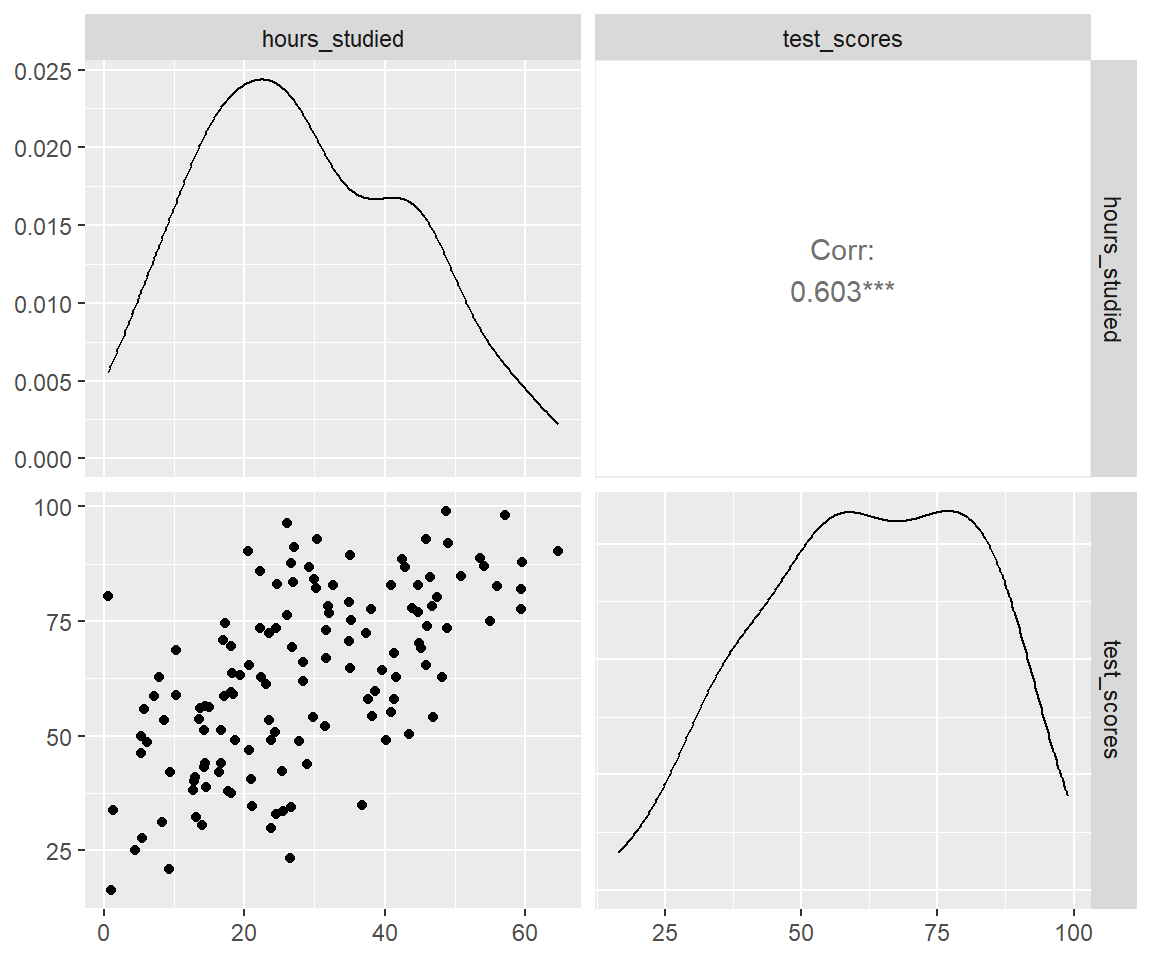
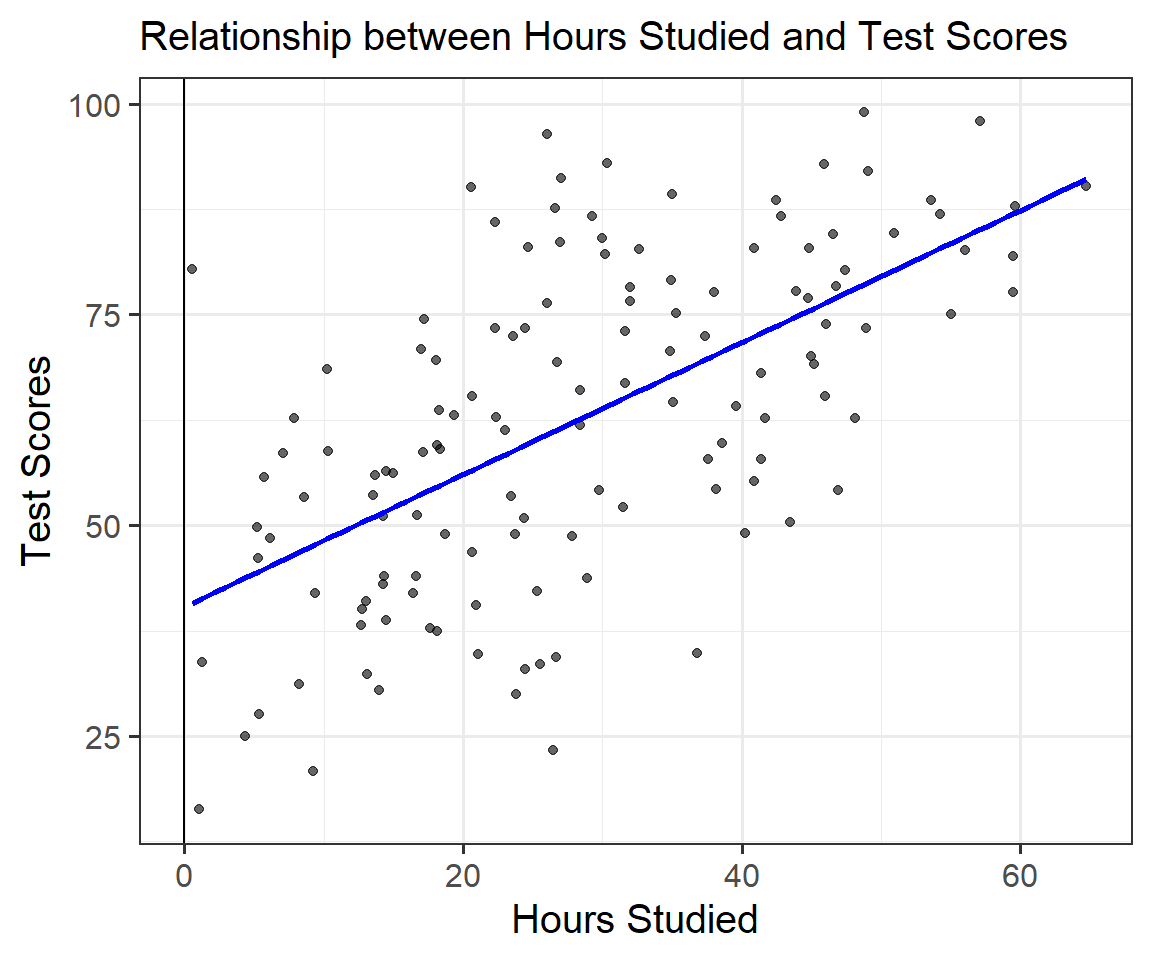
We use the regression output to construct our linear regression model:
\[scores=40 + 0.8 * hours + \varepsilon ;~~ \varepsilon \sim N(0,1)\]
| |
(1) |
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 |
| Intercept |
40.389*** |
|
(2.895) |
| Hours Studied |
0.783*** |
|
(0.090) |
| Num.Obs. |
133 |
| R2 |
0.364 |
Testing the hypothesis
We use a t-test to determine whether the regression coefficients are significantly different from zero.
The t-statistic is a ratio. The numerator is the difference between the estimated coefficient and zero (or other null hypothesis). The denominator is the standard error of the coefficient.
\[ t = \frac{\beta - 0}{se} = \frac{0.783 - 0}{0.09} = 8.7 \]
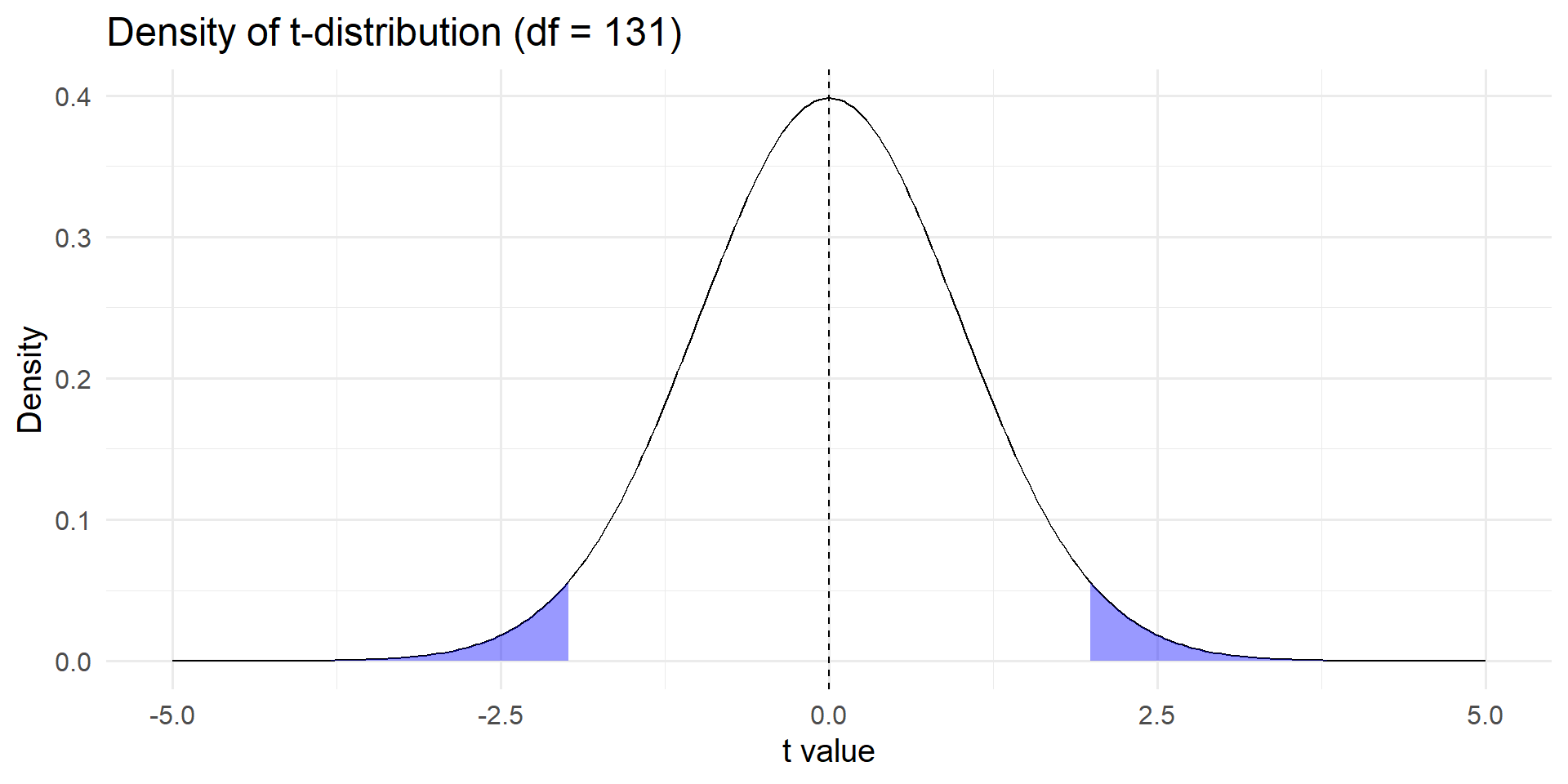
Student’s t-distribution
The shaded area is the probability that we observe the value by chance (p-value)
![]()
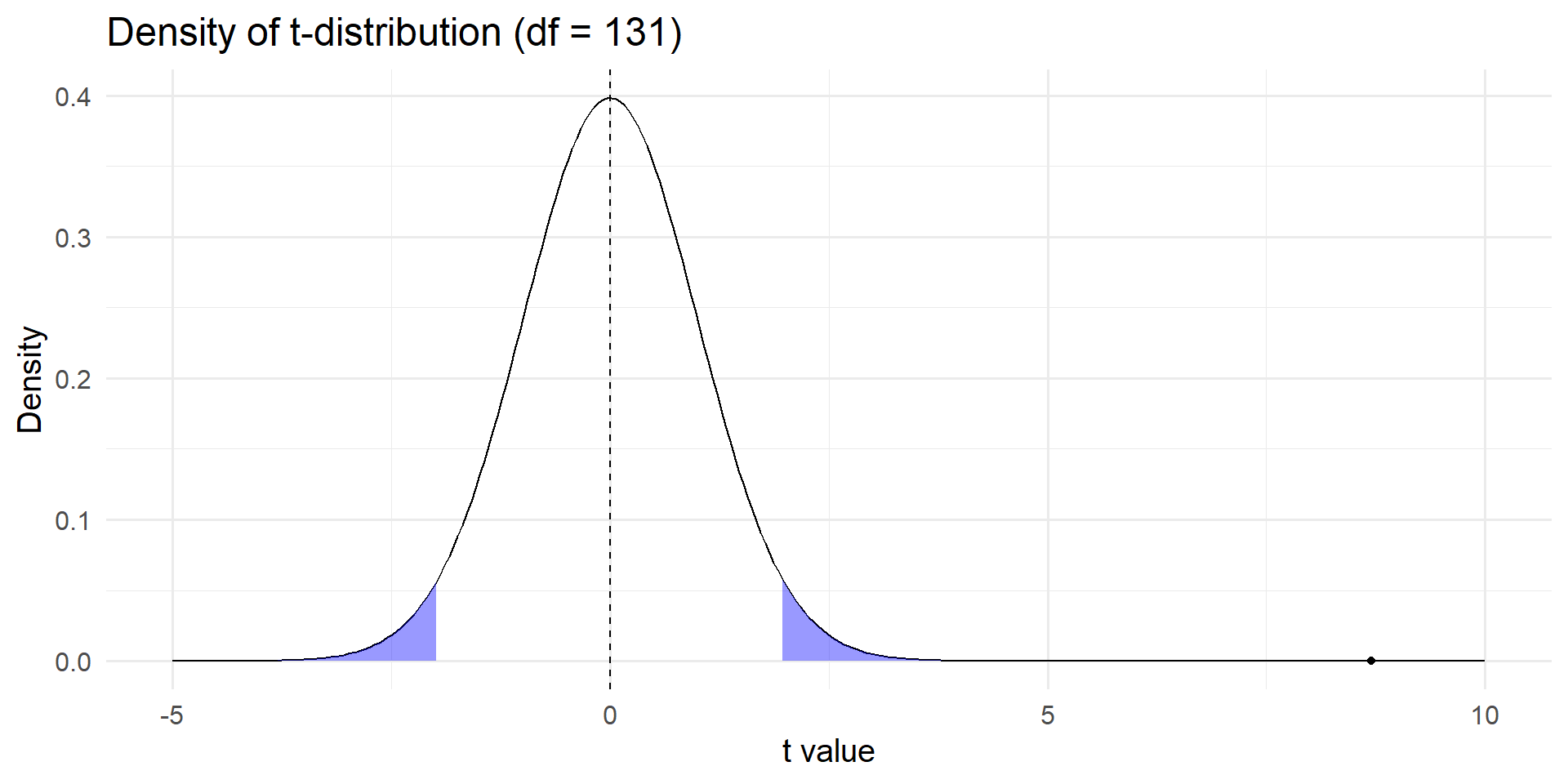
Student’s t-distribution
Locating our t-statistic on the density of the t-distribution quantifies the probability that we observe our result by chance (p-val = 1.199041e-14)
![]()
95% Confidence Interval
Reverse engineer the p-value of 0.05 to find the test statistic (1.96)
\[ 1.96 = \frac{\beta - 0}{se} \]
Then rearrange the t-statistics calculation
\[ upper = \beta + 1.96*se ; ~~~ lower = \beta - 1.96*se\]
Inference - back to the trial
The p-val = 0.00000000000001199041 suggests the probability of observing the relationship between studying and test score by chance is small.
Formally, we reject the null hypothesis H0 (no relationship) at an alpha=.05
Our test does not prove that H1 is correct, but it provides strong evidence.
Interpreting regression coefficients
| |
(1) |
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 |
| Intercept |
40.389*** |
|
(2.895) |
| Hours Studied |
0.783*** |
|
(0.090) |
| Num.Obs. |
133 |
| R2 |
0.364 |
A student that does not study is expected to get a score of 40.389.
A student’s score should improve by 0.78 points per hour of additional studying.
How many hours should a student study to get 80 points or better?
Predicting new values
We can use the coefficient estimates to calculate expected scores from new students based on study time
\[scores=40 + 0.78 * hours \]
Multivariate regression
You can add additional independent variables (a.k.a. regressors).
\[ y=\alpha + \beta_1 X_1 + \beta_2 X_2 + ... +\varepsilon \]
The \(\beta\)’s are conditional on the other covariates.
Inference is similar.
Summary
Regression is a tool to estimate relationships between variables (measurements)
When assumptions are met, the regression provides the best estimates of the relationship
Hypothesis testing helps us understand the quality of our estimates